前向分布算法
AdaBoost 就是一种前向分布算法,可以认为Adaboost算法是“模型为加法模型、损失函数为指数函数、学习算法为前向分布算法”时的二类分类学习方法。
加法模型:
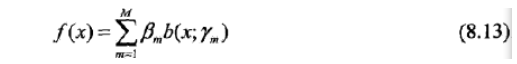
对于加法模型,在给定训练数据及损失函数L(y, f(x))的条件下,学习加法模型f(x)就成为经验风险极小化损失函数极小化问题:
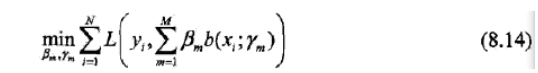
前向分布算法(forward stagewise algorithm)求解这一优化问题的想法是:
因为学习的是加法模型,那如果能够从前向后,每一步只学习一个基函数及其系数,然后逐步逼近优化目标式8.14,那么就可以简化优化的复杂度。
具体的,每步只需优化如下损失函数:
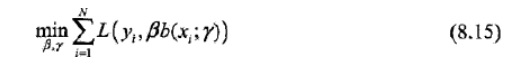
负梯度拟合
负梯度拟合利用最速下降法的近似方法,其关键是利用损失函数的负梯度在当前模型的值
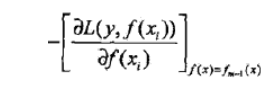
作为回归问题提升树算法中残差的近似值,拟合一个回归树。
回归

二分类,多分类
Friedman采用负二项对数似然损失函数(negative binomial log-likelihood)作为学习器的损失函数: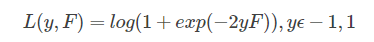
其中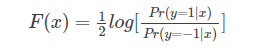
这里的 Pr(y=1|x)Pr(y=1|x) 我理解为分类器预测样本 xx 为 1 的概率,Pr(y=−1|x)Pr(y=−1|x)为分类器预测样本 xx 为 -1 的概率
计算损失函数的负梯度有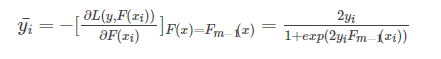
叶子节点估计值在该损失函数下的计算公式为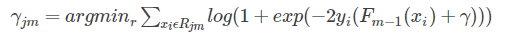
该式在论文中通过Newton-Raphson公式来近似求解,估计结果为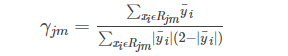
根据分类器的最终输出 F(x)F(x), 我们可以进行概率估计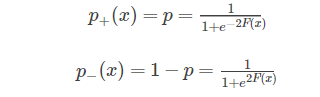
有了概率以后我们就可以利用概率进行分类
正则化
GBDT的正则化主要有三种方式。
第一种是和Adaboost类似的正则化项,即步长(learning rate)。定义为νν,对于前面的弱学习器的迭代
fk(x)=fk−1(x)+hk(x)fk(x)=fk−1(x)+hk(x)
如果我们加上了正则化项,则有
fk(x)=fk−1(x)+νhk(x)fk(x)=fk−1(x)+νhk(x)
νν的取值范围为0<ν≤10<ν≤1。对于同样的训练集学习效果,较小的νν意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
第二种正则化的方式是通过子采样比例(subsample)。取值为(0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间。
使用了子采样的GBDT有时也称作随机梯度提升树(Stochastic Gradient Boosting Tree, SGBT)。由于使用了子采样,程序可以通过采样分发到不同的任务去做boosting的迭代过程,最后形成新树,从而减少弱学习器难以并行学习的弱点。
第三种是对于弱学习器即CART回归树进行正则化剪枝。
优缺点
GBDT主要的优点有:
1) 可以灵活处理各种类型的数据,包括连续值和离散值。
2) 在相对少的调参时间情况下,预测的准备率也可以比较高。这个是相对SVM来说的。
3)使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
GBDT的主要缺点有:
1)由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。

